

Edoardo Barbieri
on 8 June 2023
Technical deep-dive into a real-time kernel

Canonical announced the general availability of Ubuntu’s real-time kernel earlier this year. Since then, our community raised several questions regarding the workings of the kernel and tuning guidelines. We aim to provide answers in this and an upcoming follow-up post.
Depending on your background knowledge, you may wish to start with the basics of preemption and a real-time system. In that case, this introductory webinar or our blog series on what is real-time Linux, is for you.
The present blog post highlights two primary test suites for Real-time Ubuntu, followed by an explanation of the components and processes involved, from the scheduler role and its different policies, to blocking spinning locks.
If you are already familiar with a real-time Linux kernel and do not wish to refresh your memory, jump to the tuning guide. There, we will go through the three primary metrics to monitor when tuning a real-time kernel, some key configs set at compile time, and a tuning example.
How to enable the real-time kernel
The real-time kernel is available via Ubuntu Pro, Canonical’s comprehensive enterprise security and compliance subscription (free for personal and small-scale commercial use in up to 5 machines) . With an Ubuntu Pro subscription, launching the kernel is as easy as:
pro attach <token>
pro enable realtime-kernel
Canonical also provides specific flavours of the real-time kernel. Optimised real-time Ubuntu, currently in beta, is also available on 12th Gen Intel® Core™ processors. Coupled with Intel® Time Coordinated Computing (Intel® TCC) and Time Sensitive Networking (IEEE TSN), the Real-time Ubuntu kernel delivers industrial-grade performance to time-bound workloads.
Real-time Ubuntu on Intel SoCs is available via Ubuntu Pro:
pro attach <token>
pro enable realtime-kernel --variant intel-iotg
Furthermore, since last September, real-time kernel Ubuntu supports Intel’s latest FlexRAN Reference Software, with optimisations to the network stack. As a user of Real-time Ubuntu, you can positively impact the open-source community by reporting any bugs you may encounter.
Testing Canonical’s real-time kernel
Real-time Ubuntu 22.04 LTS gets its real-time patches from the upstream project, maintained by the Linux Foundation, whose development closely resembles the standard procedure for the mainline kernel. Kernel developers send patches to add new functionalities or fix bugs to the upstream community via the mailing list. If approved, the maintainers apply them to the real-time patch set in the Git repo. While most of the real-time logic is in the mainline, a relevant portion, especially for locking, is still in a patch set form. Real-time Ubuntu relies on the 5.15-rt patch set, just as Ubuntu 22.04 relies on the 5.15 upstream kernel. The 5.15-rt patches, maintained by Canonical’s Joseph Salisbury, will reach end-of-life in 2026-10.
Canonical’s real-time Ubuntu relies on two primary test suites, rt-tests and stress-ng. rt-tests, maintained upstream in a Git repository, includes oslat and Cyclictest, the primary test suite upstream used to establish a baseline and determine if there is regression. Canonical routinely runs stress-ng every SRU cycle to check for regression and changes in kernel stability as well.
The real-time Ubuntu kernel relies on extensive testing, often in combination. For example, stress-ng to put a load on the system and Cyclictest to measure its latency. Furthermore, Canonical also tests the real-time kernel via partner-provided programs, like Intel’s Jitter Measurement Tool (provided as a package and not upstream).
The role of the scheduler in a real-time kernel
The scheduler is a key component of a real-time system. In the Linux kernel, a few scheduling classes, like Early Deadline First, Real-Time, and the Completely Fair Scheduler, are available, with different scheduling policies within each class, as per the table below:
| Scheduling Class | Scheduling Policy |
| EDF | SCHED_DEADLINE |
| RT | SCHED_RR |
| SCHED_FIFO | |
| CFS | SCHED_OTHER |
| SCHED_BATCH | |
| SCHED_IDLE | |
| IDLE | – |
The runqueue contains per-processor scheduling information and is the basic data structure in the scheduler. It lists the runnable processes for a given processor and is defined as a struct in kernel/sched.c.
The scheduler can be run via a call to the schedule() function. The Linux kernel will then sequentially check the EDF, RT and CFS runqueue for waiting tasks. Alternatively, the system will do an idle loop if no tasks ready to run are present.
Early Deadline First in the kernel scheduler
EDF’s scheduling policy, SCHED_DEADLINE, is deadline-based. Hence, after calling the schedule() function, the scheduler will run whichever task in the runqueue is closest to the deadline. Whereas in the POSIX (and RT class) approach, the highest-priority task gets the CPU, the runqueue’s process nearest its deadline is the next one for execution in EDF.
The unintended consequence and potential issue with the SCHED_DEADLINE policy is that in case a task was to miss its deadline, it would keep on running, causing a domino effect with the follow-on tasks also missing their deadlines. When using SCHED_DEADLINE, one must pay close attention to the system and application requirements.
The SCHED_DEADLINE policy of the EDF class specifies three vital parameters for a system, the runtime, deadline and period. The runtime denotes how long a thread will run on a processor. The deadline is the specific period of time during which a task has to complete its operation, usually measured in μs. The period states how often it will run.
Furthermore, two parameters, “scheduling deadline” and “remaining runtime”, initially set to 0, describe the task’s state. After a task wakes up, the scheduler computes a “scheduling deadline” consistent with the guarantee. In other words, when a SCHED_DEADLINE task becomes ready for execution, the scheduler checks if:
remaining runtime / (scheduling deadline – current time) > runtime / period
Real-time in the kernel scheduler
Real-time Ubuntu relies on the RT class, a POSIX fixed-priority scheduler, which provides the FIFO and RR scheduling policies, first-in-first-out and round-robin, respectively. In particular, real-time Ubuntu uses the SCHED_RR policy. SCHED_RR and SCHED_FIFO are both priority-based: the higher priority task will run on the processor by preempting the lower priority ones.
The difference between the FIFO and RR schedulers is evident when two tasks share the same priority. In the FIFO scheduler, the task that arrived first will receive the processor, running until it goes to sleep. On the other hand, in the RR scheduler, the tasks with the same priority will share the processor in a round-robin fashion.
The danger with the round-robin scheduling policy is that the CPU may spend too much time in context switching because the scheduler assigns an equal amount of runtime to each task. One can remediate such downsides by properly tuning a real-time kernel and focusing on how long tasks will run and the type of work they will do.
Completely Fair Scheduler and Idle
Finally, the generic kernel uses the CFS by default, whereas IDLE comes in handy when the system is not performing any action.
Assigning scheduling policies in code
Let’s now get our hands dirty and dive into the code directly. Assigning a task to a specific policy type is relatively straightforward. If using POSIX threads, one can set the policy when calling the pthread_attr_setschedpolicy function, as per the example below with SCHED_FIFO:
int main(int argc, char* argv[])
{
struct sched_param param;
pthread_attr_t attr;
pthread_t thread;
int ret;
…
…
…
ret = pthread_attr_setschedpolicy(&attr, SCHED_FIFO);
if (ret) {
printf("pthread setschedpolicy failed\n");
goto out;
}
…
…
…
An alternative code snippet with comments:
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0) {
printf("pthread_attr_setschedpolicy: %s\n", strerror(errno));
exit(1);
}
/* Always assign a SCHED_FIFO priority below 50-99.
* Kernel threads run in that range.
* It's never a good idea to use fifo:99 for a realtime application; the
* migration thread uses fifo:99 and all the interrupt threads run at
* fifo:50. Refer to mail on rt mailing list
*/
struct sched_param param;
memset(¶m, 0, sizeof(param));
param.sched_priority = MIN(5, sched_get_priority_max(SCHED_FIFO));
Another way is to set the policy, whether SCHED_DEADLINE, SCHED_RR or SCHED_FIFO in a sched_attr structure, as for instance in:
struct sched_attr attr = {
.size = sizeof (attr),
.sched_policy = SCHED_DEADLINE,
.sched_runtime = 10 * 1000 * 1000,
.sched_period = 2 * 1000 * 1000 * 1000,
.sched_deadline = 11 * 1000 * 1000
};
In the above, the task will repeat every two seconds and can be up to 11 μs late. The thread function would then be:
sched_setattr(0, &attr, 0);
for (;;) {
printf("sensor\n");
fflush(0);
sched_yield();
};
Another practical piece of code assigns priority to a thread. This can be done by directly passing a priority number:
param.sched_priority = 49;
ret = pthread_attr_setschedparam(&attr, ¶m);
if (ret) {
printf("pthread setschedparam failed\n");
goto out;
Assigning a sensible priority number is particularly important when working with the priority-based round-robin and FIFO policies.
An application should never run at priority 90 or higher, as that is where critical kernel threads run. Similarly, watchdogs and migration run at priority 99. Running a task at priority 99 will likely result in the overall system locking up. Hence, one should strive to set a priority below the range of 50-99 when writing a program.
Locks in a real-time kernel
There are two primary types of locks: blocking locks and spinning locks.
Blocking locks
The primary characteristic of blocking locks is that the tasks holding them can be put to sleep. Among examples of blocking locks there are counting semaphores, (per-CPU) Reader/Writer semaphores, mutexes and WW-mutexes and RT-mutexes. Of those, RT-Mutex is the only blocking lock that will not lead to priority inversion, covered in the following section.
These lock types are then converted to sleeping locks, e.g. local_lock (often used to protect CPU-specific critical data), spinlock_t and rwlock_t, when enabling preemption in a real-time Linux kernel. Further details on locking primitives and their rules are available in the Linux kernel’s documentation.
Spinning locks
Let’s now consider spinning locks. To understand their advantages, it is worth remembering classical spin locks can’t sleep and implicitly disable preemption and interrupts. In turn, this can cause unbounded latencies, which are undesirable for real-time applications, as there is no guaranteed upper boundary of execution time. Furthermore, the lock function may have to disable soft or hardware interrupts depending on the context.
In a real-time kernel, classical spin locks convert to sleepable spinlocks and are renamed raw_spinlocks. Hence, a developer may have to recode their applications and drivers to use raw spinlocks in a kernel with PREMPT_RT, depending on whether or not a spin lock is allowed to sleep.
Among spinning locks, reader/writer locks are also available. In particular, rwlock_t is a multiple reader and single writer lock mechanism. Non-PREEMPT_RT kernels implement rwlock_t as a spinning lock, with the suffix rules of spinlock_t applying accordingly.
Processes and threads
Among the reasons why PREEMPT_RT is not in mainline yet is that much of the locking within the kernel has to be updated to prevent priority inversion from occurring in a real-time environment. The present and the following section will introduce unbounded priority inversion and the need for priority inheritance.
Unbounded priority inversion
Let’s begin with priority inversion by looking at the diagram sketched below. Three tasks, L, M, and H, with varying priority levels, low, medium and high, are present in the kernel and about to contest for CPU access.
The low-priority task L runs until it takes a lock; in the diagram below, the blue bar turns red. After acquiring it, task L holds the lock and begins modifying some critical sections within the kernel.
Once the higher-priority task H appears, it preempts task L and starts to run. At this point, task H would like to acquire the same lock task L is holding. As it can’t do so, the higher-priority task H goes to sleep and waits for the lower-priority task L to release the lock. Task L thus continues running while Task H is sleeping. In such a setup, priority inversion can occur if a medium-priority task M comes along and preempts task L. Once task M starts running, the high-priority task H will potentially wait for an unbounded amount of time, preventing it from doing work in a critical kernel section. Improving the flexibility to preempt tasks executing within the kernel would thus help guarantee an upper time boundary.
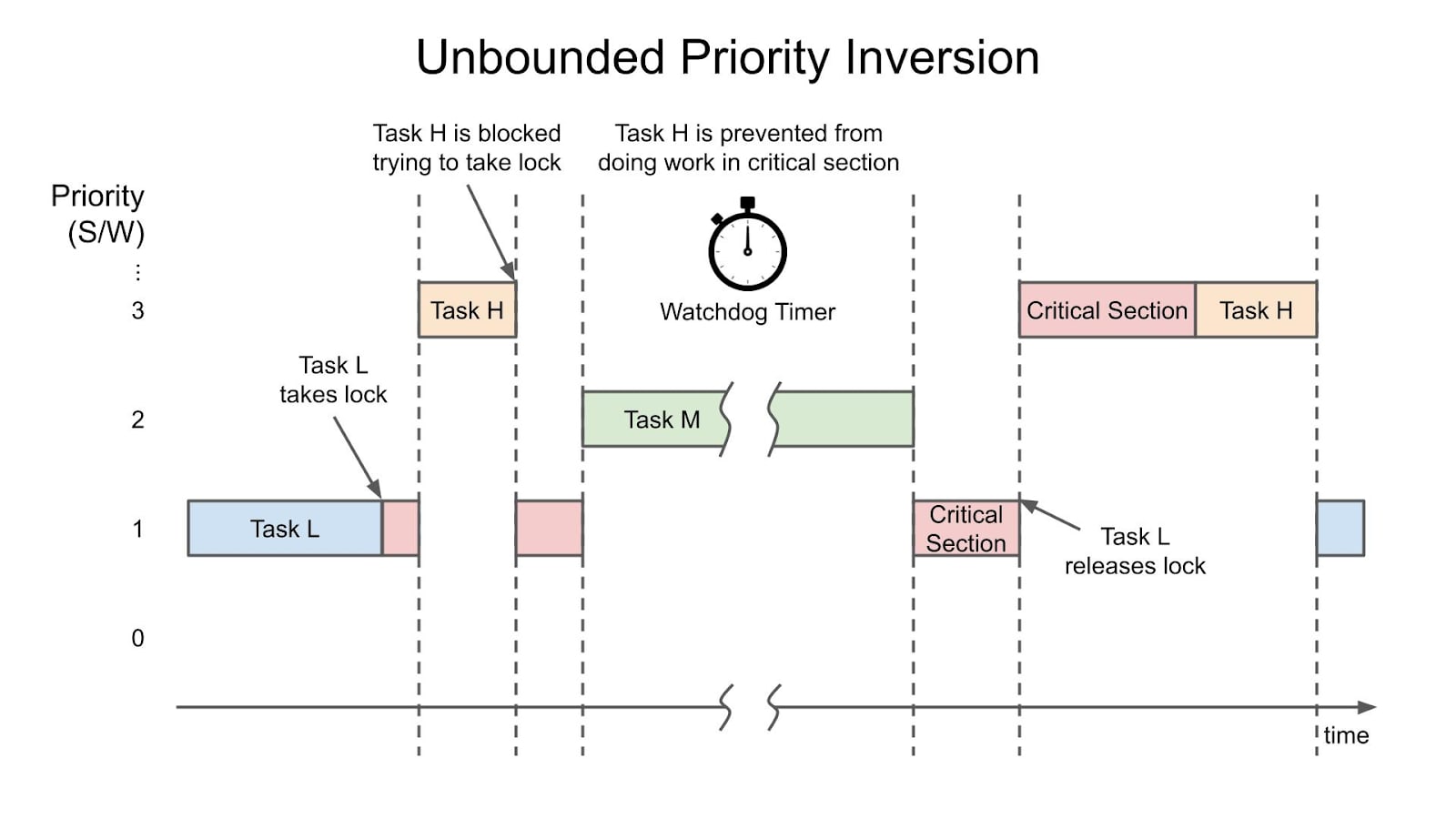
In this specific example, task M finishes running and releases the CPU – where the horizontal bar turns from green to red in the drawing – allowing task L to start running again while still holding the lock. Only once task L releases it, task H will wake up and acquire the lock, starting its work within the critical section.
Priority inversion occurred on the Mars Rover, and it is a critical challenge for developers and engineers working with real-time systems. With unbounded priority inversion, the need for priority inheritance becomes clear.
Priority Inheritance
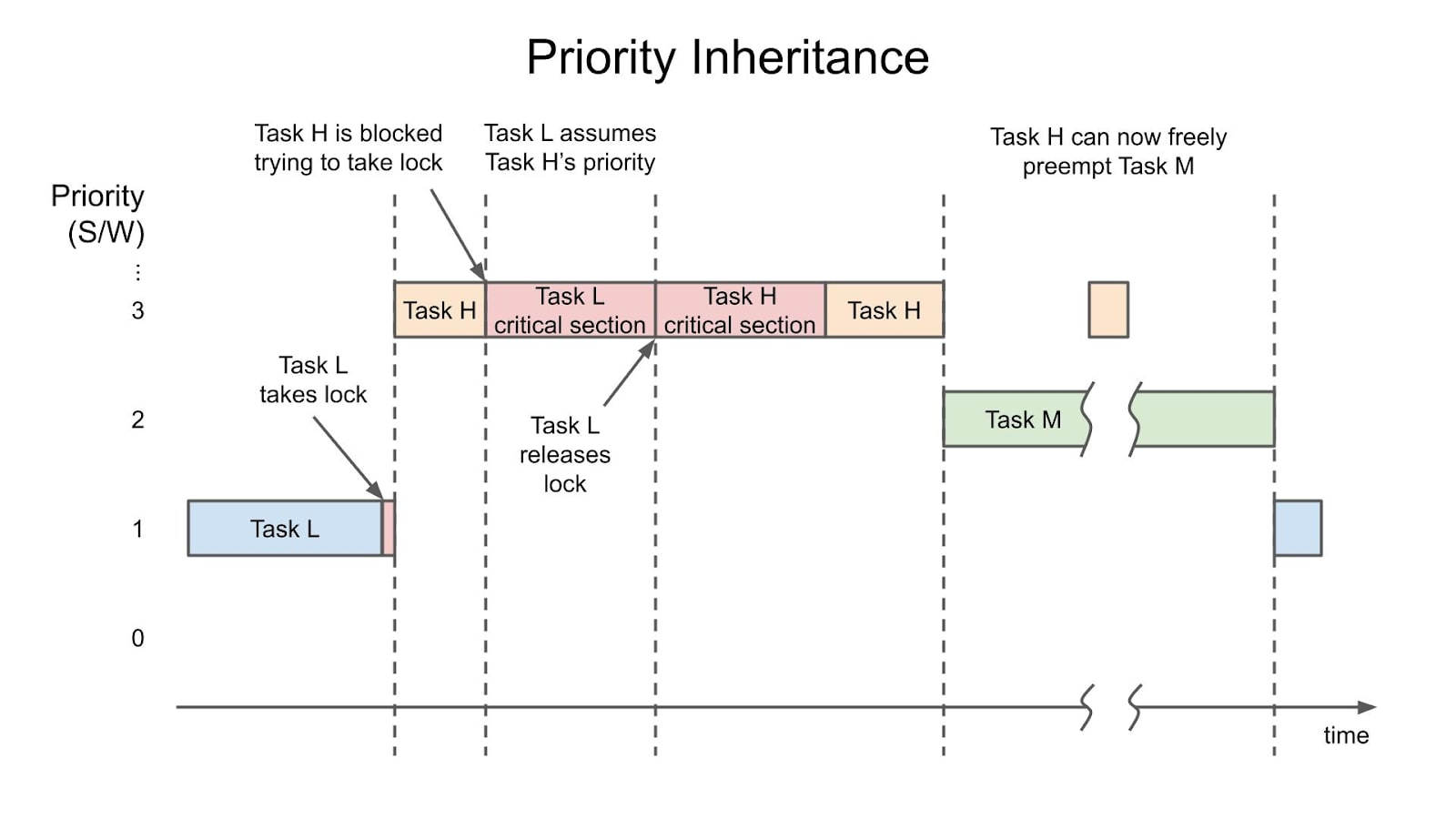
A real-time Linux kernel resolves the unbounded latencies of priority inversion via priority inheritance.
The diagram below helps illustrate the mechanism. As before, the low-priority task L starts running and acquires the lock. Similarly to the previous scenario, task H wakes up and starts running, but it is soon blocked while attempting to get the lock.
The high-priority task H wants to take the same lock held by the low-priority task L. Differently than in the priority inversion’s case, and instead of H going to sleep and waiting, priority inheritance occurs, with L acquiring H’s priority. The low-priority task L can now run with the same priority as task H, enabling it to finish its work in the critical section and then release the lock. The inheritance mechanism centres around boosting the lower task’s priority, giving it one higher than the upcoming medium priority task M, which would cause unbounded latencies.
Once task L finishes its critical section work, task H acquires the lock, where the red bar turns orange. Whenever task H completes, it will, in turn, release the lock. Only now can the medium-priority task M come along and start running. If needed, the higher-priority task H could further preempt task M to finish its processing. Priority inheritance in a real-time kernel solves the issue of task M starting to run between tasks H and L, which would give rise to unbounded latencies and priority inversion.
Further reading
This blog covered the technical foundations of a real-time Linux kernel. It is now time to learn how to improve the determinism of network latency with Linux. A system can be tuned to partition up CPU cores to perform specific tasks – for instance, a developer can assign the housekeeping core to handle all IRQ, including network interrupts using IRQ affinity, isolcpus, cpusets and tasksets. The follow-up post will introduce some relevant tuning configs when using a real-time kernel.
If you are interested in running real-time Ubuntu and are working on a commercial project, you can contact us directly. Canonical partners with silicon vendors, board manufacturers and ODMs to shorten enterprises’ time-to-market. Reach out to our team for custom board enablement, commercial distribution, long-term support or security maintenance.



